Pandas 模块 |
您所在的位置:网站首页 › performance results 82jk › Pandas 模块 |
Pandas 模块
|
目录 6. DataFrame 使用自定义函数 6.1 操作整个 DataFrame 的函数:.pipe() 6.1.1 .pipe() 语法 6.1.2 .pipe() 范例 6.2 操作行或者列的函数:.apply() 6.2.1 .apply() 语法 6.2.2 .apply() 范例 6.3 操作作单一元素的函数:.applymap() 6.3.1 .applymap() 语法 6.3.2 .applymap() 范例 如果想要应用自定义的函数,或者把其他库中的函数应用到 Pandas.DataFrame 对象中,有以下三种方法: 操作整个 DataFrame 的函数:pipe()操作行或者列的函数:apply()操作单一元素的函数:applymap() 6. DataFrame 使用自定义函数先准备数据吧 import pandas as pd dict_data={"a":list("abcdef"),"b":list("defghi"),"c":list("ghijkl")} df=pd.DataFrame.from_dict(dict_data) df得到结果
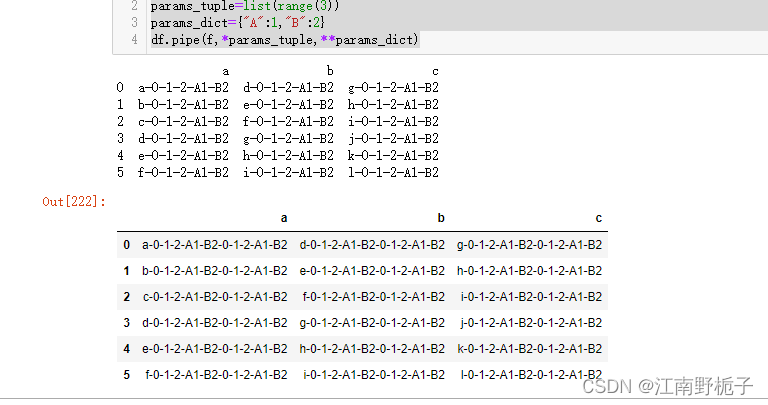
语法结构:DataFrame.pipe(func, *args, **kwargs) 参数说明: func:一个应用于Series/DataFrame的函数,*args, **kwargs都是应用于这个函数的参数args:迭代的参数,可选,可以是元组类型,也可以是列表类型或者其他。kwargs:映射的参数,可选,是一个包含关键字的字典。返回值:返回值由 func 的返回值决定 请注意,使用.pipe()时候,默认不会修改 DataFrame 本身 Help on method pipe in module pandas.core.generic: pipe(func, *args, **kwargs) method of pandas.core.frame.DataFrame instance Apply func(self, \*args, \*\*kwargs). Parameters ---------- func : function Function to apply to the Series/DataFrame. ``args``, and ``kwargs`` are passed into ``func``. Alternatively a ``(callable, data_keyword)`` tuple where ``data_keyword`` is a string indicating the keyword of ``callable`` that expects the Series/DataFrame. args : iterable, optional Positional arguments passed into ``func``. kwargs : mapping, optional A dictionary of keyword arguments passed into ``func``. Returns ------- object : the return type of ``func``. See Also -------- DataFrame.apply : Apply a function along input axis of DataFrame. DataFrame.applymap : Apply a function elementwise on a whole DataFrame. Series.map : Apply a mapping correspondence on a :class:`~pandas.Series`. Notes ----- Use ``.pipe`` when chaining together functions that expect Series, DataFrames or GroupBy objects. Instead of writing 6.1.2 .pipe() 范例.pipe()的用法非常简单,先看个代码就明白了 def f(dataframe,*args,**kwargs): for tmparg in args: dataframe+="-"+str(tmparg) for tmpkey,tmpvalue in kwargs.items(): dataframe+="-"+str(tmpkey)+str(tmpvalue) return dataframe print(df) params_tuple=list(range(3)) params_dict={"A":1,"B":2} df.pipe(f,*params_tuple,**params_dict)运行结果如下:
语法结构:DataFrame.apply(func, axis=0, raw=False, result_type=None, args=(), **kwds) 参数说明: func:一个应用于每一行或者每一列的函数。axis:{0 or 'index', 1 or 'columns'}, 默认为 0,即对行进行操作,如果设置为 1 或者 'columns' 则对列进行操作。raw :布尔值,默认为 False,这个值了决定行或者列是作为 Series 还是 ndarray类型进行传递;当值为 False 时候,每一行或者每一列都作为 Series 进行传递,为 True 时候则作为 ndarray 对象进行传递。一般情况下只有你进行 NumPy 的函数活动时候,选择 True 会获得更好的性能回报。result_type:{'expand', 'reduce', 'broadcast', None}, 默认为 None 。这个只有 axis=1,即对列 (columns) 进行操作时候才起作用。* 'expand' : 类似列表 list 的结果将转换为列。 * 'reduce' : 如果可能,返回一个序列 series ,而不是展开类似列表 list 的结果。 这与“expand”相反。 * 'broadcast' : 结果将广播到数据帧的原始形状,原始索引和列将保留。 * 默认行为 ‘None’ 取决于应用函数的返回值:类似列表list的结果将作为 series 结构结果返 回。但是,如果apply函数返回一个series ,这些序列将展开为列。 args:元组类型,是应用于 func 的参数kwds:映射的参数,可选,是一个包含关键字的字典。返回值:Series 或者 DataFrame,返回值由 func 的返回值决定 Help on method apply in module pandas.core.frame: apply(func, axis=0, raw=False, result_type=None, args=(), **kwds) method of pandas.core.frame.DataFrame instance Apply a function along an axis of the DataFrame. Objects passed to the function are Series objects whose index is either the DataFrame's index (``axis=0``) or the DataFrame's columns (``axis=1``). By default (``result_type=None``), the final return type is inferred from the return type of the applied function. Otherwise, it depends on the `result_type` argument. Parameters ---------- func : function Function to apply to each column or row. axis : {0 or 'index', 1 or 'columns'}, default 0 Axis along which the function is applied: * 0 or 'index': apply function to each column. * 1 or 'columns': apply function to each row. raw : bool, default False Determines if row or column is passed as a Series or ndarray object: * ``False`` : passes each row or column as a Series to the function. * ``True`` : the passed function will receive ndarray objects instead. If you are just applying a NumPy reduction function this will achieve much better performance. result_type : {'expand', 'reduce', 'broadcast', None}, default None These only act when ``axis=1`` (columns): * 'expand' : list-like results will be turned into columns. * 'reduce' : returns a Series if possible rather than expanding list-like results. This is the opposite of 'expand'. * 'broadcast' : results will be broadcast to the original shape of the DataFrame, the original index and columns will be retained. The default behaviour (None) depends on the return value of the applied function: list-like results will be returned as a Series of those. However if the apply function returns a Series these are expanded to columns. args : tuple Positional arguments to pass to `func` in addition to the array/series. **kwds Additional keyword arguments to pass as keywords arguments to `func`. Returns ------- Series or DataFrame Result of applying ``func`` along the given axis of the DataFrame. 6.2.2 .apply() 范例6.2.2.1 func 这次我想请大家先注意.apply() 的返回值:Series 或者 DataFrame,返回值由 func 的返回值决定 事实上,func 的特点非常重要,尤其是在和 .pipe() 做对比时候。现在以两种不同的 func 来举例说明。 第一种,func 返回值是 series 时候 def f(series): return(series.eq('1.0')) print("*"*30+"df 数据"+"*"*30) print(df) print("*"*30+"df.apply(f) 数据"+"*"*30) print(df.apply(f)) print("*"*30+"df 数据"+"*"*30) print(df)运行结果如下,返回一个 DataFrame 类型的数据,没有影响原始数据
看起来和使用 .pipe() 没什么区别
第二种,func 返回值是 series 时候 def f2(series): res="-" return(res.join(series)) print("*"*30+"df 数据"+"*"*30) print(df) print("*"*30+"df.apply(f2) 数据"+"*"*30) print(df.apply(f2)) print("*"*30+"df 数据"+"*"*30) print(df)这个时候运行结果是
而此时调用 .pipe() 的结果是
在这个地方,大家再体会一下下面的文字: 操作整个 DataFrame 的函数:pipe()操作行或者列的函数:apply()6.2.2.2 axis axis:{0 or 'index', 1 or 'columns'}, 默认为 0,即对行进行操作,如果设置为 1 或者 'columns' 则对列进行操作。
6.2.2.3 args, kwds 和 .pipe() 中类似,不再赘述 6.3 操作作单一元素的函数:.applymap() 6.3.1 .applymap() 语法语法结构:DataFrame.applymap(func, na_action: 'Optional[str]' = None) 参数说明: func : 可调用的 python 函数, 从一个单独的值(DataFrame 的元素)返回一个单独的值 (转变后的值)。 na_action: 可选,可以是 {None, 'ignore'}, 默认是 None。处理 NaN 变量,如果为 None 则不处理 NaN 对象,如果为‘ignore'则将 NaN 对象当做普通对象带入规则。 返回值:请注意,这里同样是 DataFrame。 Help on method applymap in module pandas.core.frame: applymap(func, na_action: 'Optional[str]' = None) -> 'DataFrame' method of pandas.core.frame.DataFrame instance Apply a function to a Dataframe elementwise. This method applies a function that accepts and returns a scalar to every element of a DataFrame. Parameters ---------- func : callable Python function, returns a single value from a single value. na_action : {None, 'ignore'}, default None If ‘ignore’, propagate NaN values, without passing them to func. .. versionadded:: 1.2 Returns ------- DataFrame Transformed DataFrame. 6.3.2 .applymap() 范例这是合适的 func,转换后的数据元素是之前的数据元素的重复拷贝。 def f3(value): return(value*2) print("*"*30+"df.applymap(f3) 数据"+"*"*30) print(df.applymap(f3)) print("*"*30+"df 数据"+"*"*30) print(df)运行结果为
如果想试试 na_action 用法 代码如下: def f4(value): if( pd.isna(value)): return('++NaN++') elif(pd.isnull(value)): return('++ None ++') else: return(value*2) print("*"*30+"df.applymap(f4,na_action='ignore') 数据"+"*"*30) print(df.applymap(f4,na_action='ignore' )) print("*"*30+"df.applymap(f4,na_action=None) 数据"+"*"*30) print(df.applymap(f4,na_action=None)) #也就是默认的情况运行结果如语法中所说,当 na_action = ‘ignore’ 时候,会将 NaN 值当做普通对象带入规则。
|








【本文地址】
今日新闻 |
推荐新闻 |